
 兔兔Blog
兔兔BlogT2l-Adapter

ControlNet中的T2l-Adapter模型是一种文本到图像的生成模型,它可以将文本描述转换为高质量的图像。该模型采用了类似于U-Net的编码器-解码器结构,并引入了条件生成对抗网络(cGAN)和自编码器(autoencoder)的技术,以实现从文本到图像的端到端生成。
T2l-Adapter模型的核心在于将文本信息与图像生成过程紧密结合。在模型训练过程中,输入文本被编码成向量表示,该向量随后被用作生成图像的条件信息。通过将文本向量与图像生成网络进行联合训练,T2l-Adapter学会了如何根据给定的文本描述生成相应的图像。
此外,T2l-Adapter还采用了类似于自编码器(autoencoder)的结构,以实现输入文本的自动解码和生成图像的重建。通过将解码后的图像与原始图像进行比较,模型可以学习到文本与图像之间的对应关系,从而在生成过程中更好地捕捉到文本描述的细节和语义信息。








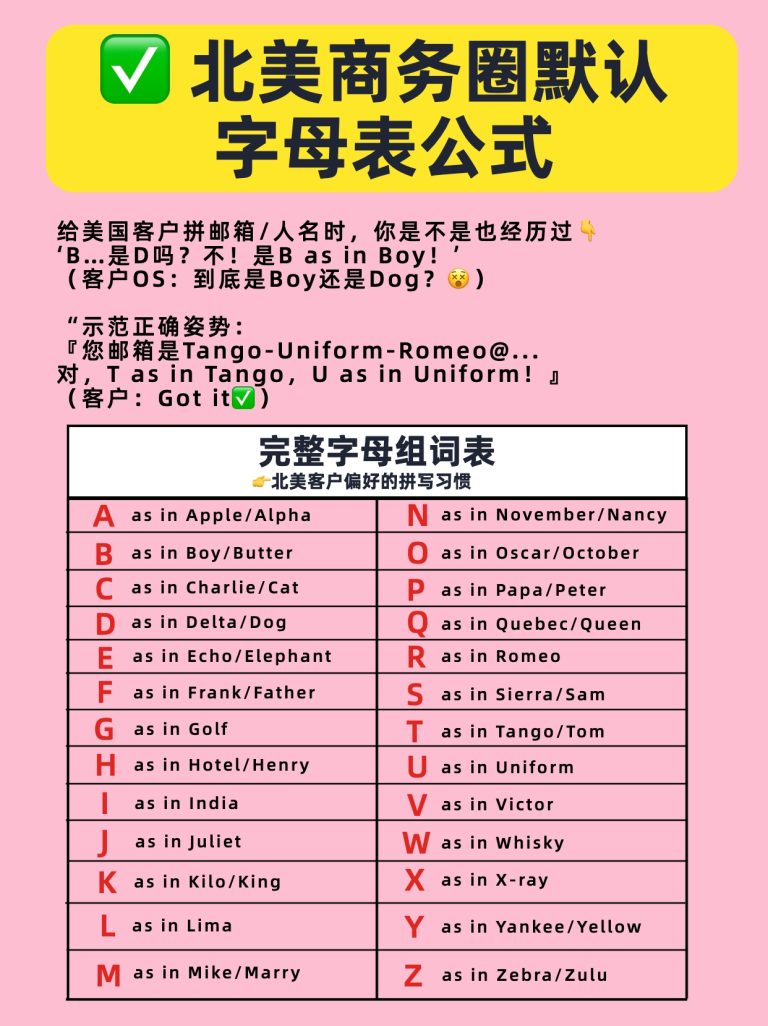
 给美国客户拼邮箱/人名时,
给美国客户拼邮箱/人名时,





























 AI作品赏析
AI作品赏析 JAVA Programming
JAVA Programming JOY MOVING
JOY MOVING Linux
Linux

最新评论
拖动图片到comfyui没反应,加载也不行,我下载的是1536*1024的png格式的
你好,可以分享工作流吗
真不错